clustering overview
| clustering | clustering tags reference |
When your traffic grows beyond the limitations of a single virtual-machine instance, Resin's clustering will manage your additional servers. With Resins' clustering, your servers gain the reliability of a triple-redundant hub, the "triad", which serves as the replicated backup of Resin's clustering system. The cluster provides automatic health checks and sensor statistics, reliable cluster-wise deployment, load-balancing, failover and distributed caching and session management.
In Resin, clustering is always enabled. Even if you only have a single server, that server belongs to its own cluster. As you add more servers, the servers are added to the cluster, and automatically gain benefits like clustered health monitoring, heartbeats, distributed management, triple redundancy, and distributed deployment.
Resin clustering gives you:
- HTTP Load balancing and failover.
- Distributed deployment and versioning of applications.
- A triple-redundant triad as the reliable cluster hub.
- Heartbeat monitoring of all servers in the cluster.
- Health sensors, metering and statistics across the cluster.
- Clustered JMS queues and topics.
- Distributed JMX management.
- Clustered caches and distributed sessions.
While most web applications start their life-cycle being deployed to a single server, it eventually becomes necessary to add servers either for performance or for increased reliability. The single-server deployment model is very simple and certainly the one developers are most familiar with since single servers are usually used for development and testing (especially on a developer's local machine). As the usage of a web application grows beyond moderate numbers, the hardware limitations of a single machine simply is not enough (the problem is even more acute when you have more than one high-use application deployed to a single machine). The physical hardware limits of a server usually manifest themselves as chronic high CPU and memory usage despite reasonable performance tuning and hardware upgrades.
Server load-balancing solves the scaling problem by letting you deploy a single web application to more than one physical machine. These machines can then be used to share the web application traffic, reducing the total workload on a single machine and providing better performance from the perspective of the user. We'll discuss Resin's load-balancing capabilities in greater detail shortly, but load-balancing is usually achieved by transparently redirecting network traffic across multiple machines at the systems level via a hardware or software load-balancer (both of which Resin supports). Load-balancing also increases the reliability/up-time of a system because even if one or more servers go down or are brought down for maintenance, other servers can still continue to handle traffic. With a single server application, any down-time is directly visible to the user, drastically decreasing reliability.
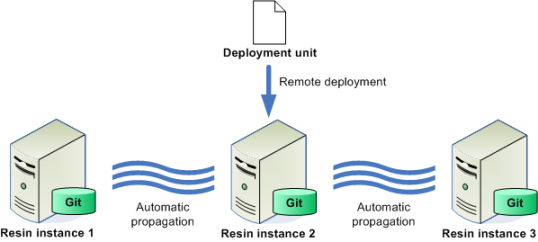
If your application runs on multiple servers, Resin's clustered deployment helps you updating new versions of your application to all servers, and verify that all servers in the cluster are running the same version. When you deploy a new version, Resin ensures that all servers have an identical copy, validates the application, and then deploys it consistently. The clustered deployment is reliable across failures because its built on a transactional version control system (Git). After a new server starts or a failed server restarts, it checks with the redundant triad for the latest application version, copying it as necessary and deploying it.
If web applications were entirely stateless, load-balancing alone would be sufficient in meeting all application server scalability needs. In reality, most web applications are relatively heavily stateful. Even very simple web applications use the HTTP session to keep track of current login, shopping-cart-like functionality and so on. Component oriented web frameworks like JSF and Wicket in particular tend to heavily use the HTTP session to achieve greater development abstraction. Maintaining application state is also very natural for the CDI (Resin CanDI) and Seam programming models with stateful, conversational components. When web applications are load-balanced, application state must somehow be shared across application servers. While in most cases you will likely be using a sticky session (discussed in detail shortly) to pin a session to a single server, sharing state is still important for fail-over. Fail-over is the process of seamlessly transferring over an existing session from one server to another when a load-balanced server fails or is taken down (probably for upgrade). Without fail-over, the user would lose a session when a load-balanced server experiences down-time. In order for fail-over to work, application state must be synchronized or replicated in real time across a set of load-balanced servers. This state synchronization or replication process is generally known as clustering. In a similar vein, the set of synchronized, load-balanced servers are collectively called a cluster. Resin supports robust clustering including persistent sessions, distributed sessions and dynamically adding/removing servers from a cluster (elastic/cloud computing).
Based on the infrastructure required to support load-balancing, fail-over and clustering, Resin also has support for a distributed caching API, clustered application deployment as well as tools for administering the cluster.
The simplest mechanism for doing deployment in a clustered environment is to copy files to each server's deployment directory. The biggest issue with this approach is that it is very difficult to synchronize deployment across the cluster and it often results in some down-time. Resin clustered deployment is designed to solve this problem. Resin has ANT and Maven based APIs to deploy to a cluster in an automated fashion. These features work much like session clustering in that applications are automatically replicated across the cluster. Because Resin cluster deployment is based on Git, it also allows for application versioning and staging across the cluster.
Although the upload and copy of application archives is common for single servers, it becomes more difficult to manage as your site scales to multiple servers. Along with the mechanics of copying the same file many times, you also need to consider the synchronization of applications across all the servers, making sure that each server has a complete, consistent copy. The benefits of using Resin's clustered deployment include:
- Verify complete upload by secure digest before deployment begins.
- Verify all servers receive the same copy of the application.
- Versioned deployment, including transparent user upgrades.
Because each organization has different deployment strategies, Resin provides several deployment techniques to match your internal deployment strategy:
- Upload and copy .war files individually.
- Use from command-line with "deploy" command.
- Use /resin-admin deploy form.
- Use ant script with Resin's deployment plugin.
- Use maven script with Resin's deployment plugin.
As an example, the command-line deployment of a .war file to a running Resin instance looks like the following:
unix> bin/resin.sh deploy test.war -user my-user -password my-pass Deployed production/webapp/default/test from /home/caucho/ws/test.war to http://192.168.1.10:8080/hmtp
In order to use Resin clustered deployment, you must first enable remote deployment on the server, which is disabled by default for security. You do this using the following Resin configuration:
<resin xmlns="http://caucho.com/ns/resin"
xmlns:resin="urn:java:com.caucho.resin">
<cluster id="app-tier">
<resin:AdminAuthenticator password-digest="none">
<resin:user name="my-user" password="my-pass"/>
</resin:AdminAuthenticator>
<resin:RemoteAdminService/>
<resin:DeployService/>
...
</cluster>
</resin>
In the example above, both the remote admin service and the deployment service is enabled. Note, the admin authenticator must be enabled for any remote administration and deployment for obvious security reasons. To keep things simple, we used a clear-text password above, but you should likely use a password hash instead.
The output exposes a few important details about the underlying remote deployment implementation for Resin that you should understand. Remote deployment for Resin uses Git under the hood. In case you are not familiar with it, Git is a newish version control system similar to Subversion. A great feature of Git is that it is really clever about avoiding redundancy and synchronizing data across a network. Under the hood, Resin stores deployed files as nodes in Git with tags representing the type of file, development stage, virtual host, web application context root name and version. The format used is this:
stage/type/host/webapp[-version]
In the example, all web applications are stored under , we didn't specify a stage or virtual host in the Ant task so is used, the web application root is foo and no version is used since one was not specified. This format is key to the versioning and staging featured we will discuss shortly.
As soon as your web application is uploaded to the Resin deployment repository, it is propagated to all the servers in the cluster - including any dynamic servers that are added to the cluster at a later point in time after initial propagation happens.
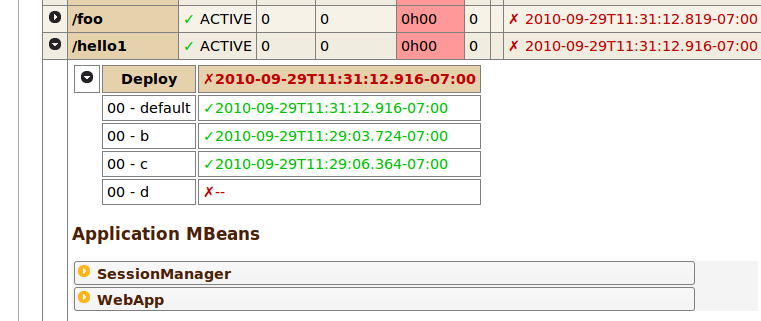
When you deploy an application, it's always a good idea to check that all servers in the cluster have received the correct web-app. Because Resin's deployment is based on a transactional version-control system, you can compare the exact version across all servers in the cluster using the /resin-admin web-app page.
The following screenshot shows the /hello1 webapp deployed across the cluster using a .war deployment in the webapps/ directory. Each version (date) is in green to indicate that the hash validation matches for each server. If one server had a different content, the date would be marked with a red 'x'.
The details for each Ant and Maven based clustered deployment API is outlined here.
Once your traffic increases beyond the capacity of a single application server, your site needs to add a HTTP load balancer as well as the second application server. Your system is now a two tier system: an app-tier with your program and a web-tier for HTTP load-balancing and HTTP proxy caching. Since the load-balancing web-tier is focusing on HTTP and proxy caching, you can usually handle many app-tier servers with a single web-tier load balancer. Although the largest sites will pay for an expensive hardware load balancer, medium and small sites can use Resin's built-in load-balancer as a cost-effective and efficient way to scale a moderate number of servers, while gaining the performance advantage of Resin's HTTP proxy caching.
A load balanced system has three main requirements: define the servers to use as the application-tier, define the servers in the web-tier, and select which requests are forwarded (proxied) to the backend app-tier servers. Since Resin's clustering configuration already defines the servers in a cluster, the only additional configuration is to use the <resin:LoadBalance> tag to forward request to the backend.
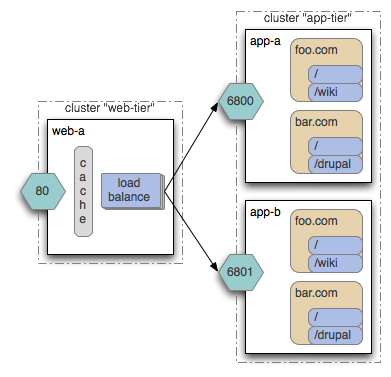
Dispatching requests with load balancing in Resin is accomplished through the <resin:LoadBalance> tag placed on a cluster. In effect, the <resin:LoadBalance> tag turns a set of servers in a cluster into a software load-balancer. This makes a lot of sense in light of the fact that as the traffic on your application requires multiple servers, your site will naturally be split into two tiers: an application server tier for running your web applications and a web/HTTP server tier talking to end-point browsers, caching static/non-static content, and distributing load across servers in the application server tier.
The best way to understand how this works is through a simple example configuration. The following resin.xml configuration shows servers split into two clusters: a web-tier for load balancing and HTTP, and an app-tier to process the application:
<resin xmlns="http://caucho.com/ns/resin"
xmlns:resin="urn:java:com.caucho.resin">
<cluster-default>
<resin:import path="${__DIR__}/app-default.xml"/>
</cluster-default>
<cluster id="app-tier">
<server id="app-a" address="192.168.0.10" port="6800"/>
<server id="app-b" address="192.168.0.11" port="6800"/>
<host id="">
<web-app id="" root-directory="/var/www/htdocs"/>
</host>
</cluster>
<cluster id="web-tier">
<server id="web-a" address="192.168.0.1" port="6800">
<http port="80"/>
</server>
<proxy-cache memory-size="256M"/>
<host id="">
<resin:LoadBalance regexp="" cluster="app-tier"/>
</host>
</cluster>
</resin>
In the configuration above, the cluster server load balances across the cluster servers because of the attribute specified in the <resin:LoadBalance> tag. The <cache> tag enables proxy caching at the web tier. The web-tier forwards requests evenly and skips any app-tier server that's down for maintenance/upgrade or restarting due to a crash. The load balancer also steers traffic from a single session to the same app-tier server (a.k.a sticky sessions), improving caching and session performance.
Each app-tier server produces the same application because they have the same virtual hosts, web-applications and Servlets, and use the same resin.xml. Adding a new machine just requires adding a new <server> tag to the cluster. Each server has a unique name like "app-b" and a TCP cluster-port consisting of an <IP,port>, so the other servers can communicate with it. Although you can start multiple Resin servers on the same machine, TCP requires the <IP,port> to be unique, so you might need to assign unique ports like 6801, 6802 for servers on the same machine. On different machines, you'll use unique IP addresses. Because the cluster-port is for Resin servers to communicate with each other, they'll typically be private IP addresses like 192.168.1.10 and not public IP addresses. In particular, the load balancer on the web-tier uses the cluster-port of the app-tier to forward HTTP requests.
All three servers will use the same resin.xml, which makes managing multiple server configurations pretty easy. The servers are named by the server attribute, which must be unique, just as the <IP,port>. When you start a Resin instance, you'll use the server-id as part of the command line:
192.168.0.10> java -jar lib/resin.jar -server app-a start 192.168.0.11> java -jar lib/resin.jar -server app-b start 192.168.0.1> java -jar lib/resin.jar -server web-a start
Since Resin lets you start multiple servers on the same machine, a small site might start the web-tier server and one of the app-tier servers on one machine, and start the second server on a second machine. You can even start all three servers on the same machine, increasing reliability and easing maintenance, without addressing the additional load (although it will still be problematic if the physical machine itself and not just the JVM crashes). If you do put multiple servers on the same machine, remember to change the to something like 6801, etc so the TCP binds do not conflict.
In the /resin-admin management page, you can manage all three servers at once, gathering statistics/load and watching for any errors. When setting up /resin-admin on a web-tier server, you'll want to remember to add a separate <web-app> for resin-admin to make sure the <rewrite-dispatch> doesn't inadvertantly send the management request to the app-tier.
Sticky/Persistent Sessions
To understand what sticky sessions are and why they are important, it is easiest to see what will happen without them. Let us take our previous example and assume that the web tier distributes sessions across the application tier in a totally random fashion. Recall that while Resin can replicate the HTTP session across the cluster, it does not do so by default. Now lets assume that the first request to the web application resolves to app-a and results in the login being stored in the session. If the load-balancer distributes sessions randomly, there is no guarantee that the next request will come to app-a. If it goes to app-b, that server instance will have no knowledge of the login and will start a fresh session, forcing the user to login again. The same issue would be repeated as the user continues to use the application from in what their view should be a single session with well-defined state, making for a pretty confusing experience with application state randomly getting lost!
One way to solve this issue would be to fully synchronize the session across the load-balanced servers. Resin does support this through its clustering features (which is discussed in detail in the following sections). The problem is that the cost of continuously doing this synchronization across the entire cluster is very high and relatively unnecessary. This is where sticky sessions come in. With sticky sessions, the load-balancer makes sure that once a session is started, any subsequent requests from the client go to the same server where the session resides. By default, the Resin load-balancer enforces sticky sessions, so you don't really need to do anything to enable it.
Resin accomplishes this by encoding the session cookie with the host name that started the session. Using our example, the hosts would generate cookies like this:
| INDEX | COOKIE PREFIX |
|---|---|
| 1 | xxx |
| 2 | xxx |
On the web-tier, Resin decoded the session cookie and sends it to the appropriate server. So will go to app-b. If app-b fails or is down for maintenance, Resin will send the request a backup server calculated from the session id, in this case app-a. Because the session is not clustered, the user will lose the session but they won't see a connection failure (to see how to avoid losing the session, check out the following section on clustering).
Manually Choosing a Server
For testing purposes you might want to send requests to a specific servers in the app-tier manually. You can easily do this since the web-tier uses the value of the to maintain sticky sessions. You can include an explicit to force the web-tier to use a particular server in the app-tier.
Since Resin uses the first character of the to identify the server to use, starting with 'a' will resolve the request to app-a. If wwww.example.com resolves to your web-tier, then you can use values like this for testing:
- http://www.example.com/proxooladmin;jsessionid=aaaXXXXX
- http://www.example.com/proxooladmin;jsessionid=baaXXXXX
- http://www.example.com/proxooladmin;jsessionid=caaXXXXX
- http://www.example.com/proxooladmin;jsessionid=daaXXXXX
- http://www.example.com/proxooladmin;jsessionid=eaaXXXXX
- etc.
You can also use this fact to configure an external sticky load-balancer (likely a high-performance hardware load-balancer) and eliminate the web tier altogether. In this case, this is how the Resin configuration might look like:
<resin xmlns="http://caucho.com/ns/resin">
<cluster id="app-tier">
<server-default>
<http port='80'/>
</server-default>
<server id='app-a' address='192.168.0.1' port="6800"/>
<server id='app-b' address='192.168.0.2' port="6800"/>
<server id='app-c' address='192.168.0.3' port="6800"/>
</cluster>
</resin>
Each server will be started as , , etc to grab its specific configuration.
Socket Pooling, Timeouts, and Failover
For efficiency, Resin's load balancer manages a pool of sockets connecting to the app-tier servers. If Resin forwards a new request to an app-tier server and it has an idle socket available in the pool, it will reuse that socket, improving performance and minimizing network load. Resin uses a set of timeout values to manage the socket pool and to handle any failures or freezes of the backend servers. The following diagram illustrates the main timeout values:
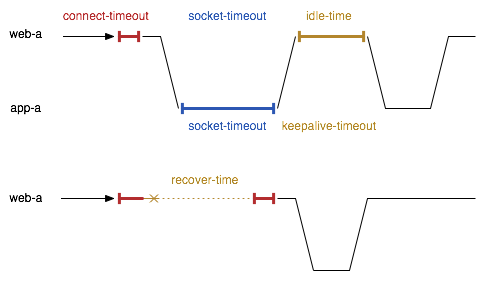
- load-balance-connect-timeout: the load balancer timeout
for the
connect()system call to complete to the app-tier (5s). - load-balance-idle-time: load balancer timeout for an idle socket before closing it automatically (5s).
- load-balance-recover-time: the load balancer connection failure wait time before trying a new connection (15s).
- load-balance-socket-timeout: the load balancer timeout for a valid request to complete (665s).
- keepalive-timeout: the app-tier timeout for a keepalive connection (15s)
- socket-timeout: the app-tier timeout for a read or write (65s)
When an app-tier server is down due to maintenance or a crash, Resin will use the load-balance-recover-time as a delay before retrying the downed server. With the failover and recover timeout, the load balancer reduces the cost of a failed server to almost no time at all. Every recover-time, Resin will try a new connection and wait for load-balance-connect-timeout for the server to respond. At most, one request every 15 seconds might wait an extra 5 seconds to connect to the backend server. All other requests will automatically go to the other servers.
The socket-timeout values tell Resin when a socket connection is dead and should be dropped. The web-tier timeout load-balance-socket-timeout is much larger than the app-tier timeout socket-timeout because the web-tier needs to wait for the application to generate the response. If your application has some very slow pages, like a complicated nightly report, you may need to increase the load-balance-socket-timeout to avoid the web-tier disconnecting it.
Likewise, the load-balance-idle-time and keepalive-timeout are a matching pair for the socket idle pool. The idle-time tells the web-tier how long it can keep an idle socket before closing it. The keepalive-timeout tells the app-tier how long it should listen for new requests on the socket. The keepalive-timeout must be significantly larger than the load-balance-idle-time so the app-tier doesn't close its sockets too soon. The keepalive timeout can be large since the app-tier can use the keepalive-select manager to efficiently wait for many connections at once.
resin:LoadBalance Dispatching
<resin:LoadBalance> is part of Resin's rewrite capabilities, Resin's equivalent of the Apache mod_rewrite module, providing powerful and detailed URL matching and decoding. More sophisticated sites might load-balance based on the virtual host or URL using multiple <resin:LoadBalance> tags.
In most cases, the web-tier will dispatch everything to the app-tier servers. Because of Resin's proxy cache, the web-tier servers will serve static pages as fast as if they were local pages.
In some cases, though, it may be important to send different requests to different backend clusters. The <resin:LoadBalance> tag can choose clusters based on URL patterns when such capabilities are needed.
The following rewrite example keeps all *.png, *.gif, and *.jpg files on the web-tier, sends everything in /foo/* to the foo-tier cluster, everything in /bar/* to the bar-tier cluster, and keeps anything else on the web-tier.
<resin xmlns="http://caucho.com/ns/resin"
xmlns:resin="urn:java:com.caucho.resin">
<cluster-default>
<resin:import path="${__DIR__}/app-default.xml"/>
</cluster-default>
<cluster id="web-tier">
<server id="web-a">
<http port="80"/>
</server>
<proxy-cache memory-size="64m"/>
<host id="">
<web-app id="/">
<resin:Dispatch regexp="(\.png|\.gif|\.jpg)"/>
<resin:LoadBalance regexp="^/foo" cluster="foo-tier"/>
<resin:LoadBalance regexp="^/bar" cluster="bar-tier"/>
</web-app>
</host>
</cluster>
<cluster id="foo-tier">
...
</cluster>
<cluster id="bar-tier">
...
</cluster>
</resin>
For details on the tags used for clustering, please refer to this page.
After many years of developing Resin's distributed clustering for a wide variety of user configurations, we refined our clustering network to a hub-and-spoke model using a triple-redundant triad of servers as the cluster hub. The triad model provides interlocking benefits for the dynamically scaling server configurations people are using.
- When you bring down one server for maintenance, the triple redundancy continues to maintain reliability.
- You can add and remove dynamic servers safely without affecting the redundant state.
- Your network processing will be load-balanced across three servers, eliminating a single point of failure.
- Your servers will scale evenly across the cluster pod because each new server only needs to speak to the triad, not all servers.
- Your large site can split the cluster into independent "pods" of less than 64-servers to maintain scalability.
Cluster Heartbeat
As part of Resin's health check system, the cluster continually checks that all servers are alive and responding properly. Every 60 seconds, each server sends a heartbeat to the triad, and each triad server sends a heartbeat to all the other servers.
When a server failure is detected, Resin immediately detects the failure, logging it for an administrator's analysis and internally prepares to failover to backup servers for any messaging for distributed storage like the clustered sessions and the clustered deployment.
When the server comes back up, the heartbeat is reestablished and any missing data is recovered.
Because load balancing, maintenance and failover should be invisible to your users, Resin can replicate user's session data across the cluster. When the load-balancer fails over a request to a backup server, or when you dynamically remove a server, the backup can grab the session and continue processing. From the user's perspective, nothing has changed. To make this process fast and reliable, Resin uses the triad servers as a triplicate backup for the user's session.
The following is a simple example of how to enable clustering on Resin:
<web-app xmlns="http://caucho.com/ns/resin">
<session-config>
<use-persistent-store="true"/>
</session-config>
</web-app>
The <use-persistent-store> tag under <session-config> is used to enable clustering. Note, clustering is enabled on a per-web-application basis because not all web applications under a host need be clustered. If you want to cluster all web applications under a host, you can place <use-persistent-store> under <web-app-default>. The following example shows how you can do this:
<resin xmlns="http://caucho.com/ns/resin">
<cluster>
<server id="a" address="192.168.0.1" port="6800"/>
<server id="b" address="192.168.0.2" port="6800"/>
<web-app-default>
<session-config use-persistent-store="true"/>
</web-app-default>
</cluster>
</resin>
The above example also shows how you can override the clustering behaviour for Resin. By default, Resin uses a triad based replication with all three triad servers backing up the data server. THe <persistent-store type="cluster"> has a number of other attributes:
| ATTRIBUTE | DESCRIPTION | DEFAULT |
|---|---|---|
| always-save | Always save the value | false |
| max-idle-time | How long idle objects are stored (session-timeout will invalidate items earlier) | 24h |
The cluster store is valuable for single-server configurations, because Resin stores a copy of the session data on disk, allowing for recovery after system restart. This is basically identical to the file persistence feature discussed below.
always-save-session
Resin's distributed sessions need to know when a session has changed in order to save/synchronize the new session value. Although Resin does detect when an application calls , it can't tell if an internal session value has changed. The following Counter class shows the issue:
package test;
public class Counter implements java.io.Serializable {
private int _count;
public int nextCount() { return _count++; }
}
Assuming a copy of the Counter is saved as a session attribute, Resin doesn't know if the application has called . If it can't detect a change, Resin will not backup/synchronize the new session, unless is set on the <session-config>. When is true, Resin will back up the entire session at the end of every request. Otherwise, a session is only changed when a change is detected.
... <web-app id="/foo"> ... <session-config> <use-persistent-store/> <always-save-session/> </session-config> ... </web-app>
Serialization
Resin's distributed sessions relies on Hessian serialization to save and restore sessions. Application objects must implement for distributed sessions to work.
No Distributed Locking
Resin's clustering does not lock sessions for replication. For browser-based sessions, only one request will typically execute at a time. Because browser sessions have no concurrency, there's really no need for distributed locking. However, it's a good idea to be aware of the lack of distributed locking in Resin clustering.
For details on the tags used for clustering, please refer to this page.
Distributed caching is a very useful technique for reducing database load and increasing application performance. Resin provides a very simple JSR-107 JCache based distributed caching API. Distributed caching in Resin basically leverages the underlying infrastructure used to support load balancing, clustering and session/state replication. Note, since Resin clustering is not transactional, Resin distributed caching is also not transactional and does not use locking.
The first step to using Resin distributed caching is to configure a cache. You configure a named distributed cache at the web application level like this:
<resin xmlns="http://caucho.com/ns/resin"
xmlns:cluster="urn:java:com.caucho.distcache">
<cluster id="">
<host id="">
<web-app id="">
<cluster:ClusterCache>
<cluster:name>test</cluster:name>
</cluster:ClusterCache>
</web-app>
</host>
</cluster>
</resin>
You may then inject the cache through CDI and use it in your application via the JCache API:
import javax.cache.*;
...
@Inject
private Cache cache;
...
if (cache.get("discount_rate") != null) {
cache.put("discount_rate", discountRate);
}
| clustering | clustering tags reference |
| Copyright © 1998-2011 Caucho Technology, Inc. All rights reserved. Resin ® is a registered trademark, and Quercustm, Ambertm, and Hessiantm are trademarks of Caucho Technology. |